Hugging Face与NLP预训练模型
这一节我们来学习基于Hugging Face的NLP预训练模型的使用方式,包括Bert。
先来了解一些背景知识。
背景
深度学习
我们前面用的BOW,贝叶斯,SVM,LR,XGBoost都是传统机器学习范畴,深度学习的特点是通过设计不同的神经网络来完成各种任务,自从兴起以来,它在分类、监测、识别、生成等领域取得了远声誉传统机器学习方法的效果,已经成为人工智能的代名词。
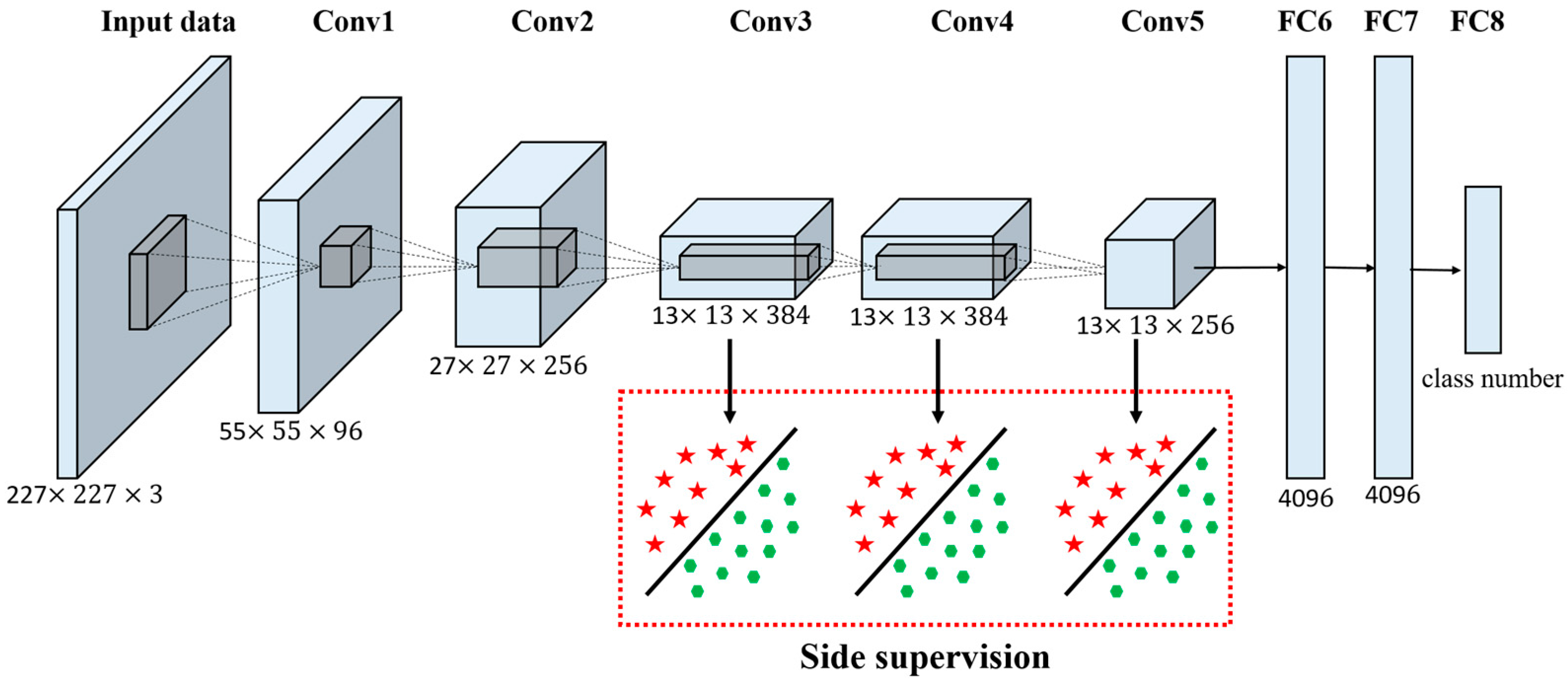

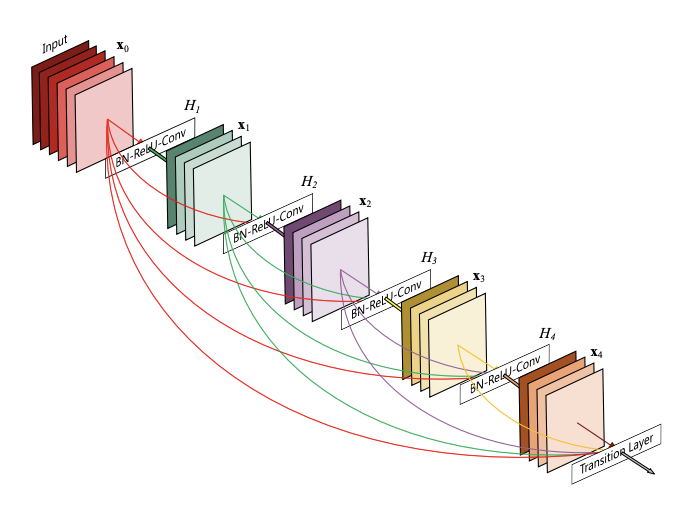
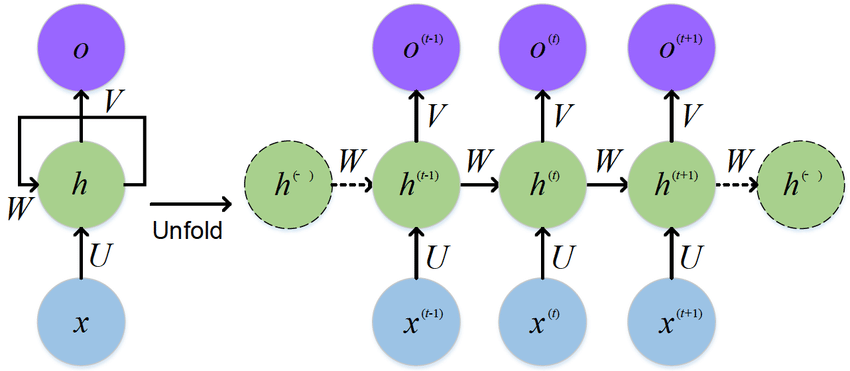
预训练与微调
预训练是让某一神经网络从大规模数据中获得与具体任务无关的参数的训练,并将得到的参数和模型保存出来。它采用的数据规模是如此之大,以至于不论我们在具体任务中用的什么类型的数据,都已经被它学习过了,都可以胜任我们的任务。
如果我们觉得还不放心,或者存在标签不一致的问题,还可以做一下微调,即再在我们的数据上做一个简单训练,让预训练参数适应于我们的数据,然后再进行测试。
BERT
BERT全称为Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder。模型的主要创新点都在pre-train方法上,通过预训练和精调横扫了11项NLP任务,提出当年就成为NLP领域大火、整个人工智能学界都有所耳闻的模型。目前已经是NLP领域里程碑式的方法。
Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
Hugging Face

Hugging Face是一家总部位于纽约的聊天机器人初创服务商,但更令它广为人知的是Hugging Face专注于NLP技术,拥有大型的开源社区。尤其是在github上开源的自然语言处理预训练模型库 Transformers,已被下载超过一百万次,github上超过24000个star。Transformers 提供了NLP领域大量state-of-art的预训练语言模型结构的模型和调用框架。
简单来说就是Hugging Face提供了一个库,名为 Transformers,包含大量预训练模型,以供人们使用。
为什么使用transformers?
- 表现优越,高级抽象,只有三个类,对所有模型有同一的API;
- 社区中有研究人员分享的数十种亿万级的模型架构、两千多个预训练模型、100多种语言支持,不止BERT;
- 使用简单。
使用Hugging Face的预训练模型
安装
首先是安装Hugging Face的transformers包。这个包依赖于Python 3.6+、Flax 0.3.2+、PyTorch 1.3.1+ 和 TensorFlow 2.3+等环境,最好在有深度学习级GPU的电脑上进行安装。配置好依赖后,使用pip进行安装:
pip install transformers简单使用
transformers提供了 pipeline (流水线)API,聚合了多种多样的预训练模型和对应的文本预处理。
下面是一个快速使用流水线去判断正负面情绪的例子:
>>> from transformers import pipeline
# 使用情绪分析流水线
>>> classifier = pipeline('sentiment-analysis')
>>> print(classifier('I love you more and more each day as time goes by'))
[{'label': 'POSITIVE', 'score': 0.9998432397842407}]
>>> print(classifier('有你的每一天都很开心'))
[{'label': 'POSITIVE', 'score': 0.662761926651001}]第二行代码下载并缓存了 pipeline 使用的默认预训练模型,而第三行代码则在给定的文本上进行了评估。这里的sore表示答案“正面” (positive) 具有 99 %的置信度。
下面是一个简单的从给定文本中抽取问题答案的例子:
>>> from transformers import pipeline
# 使用问答流水线
>>> question_answerer = pipeline('question-answering')
>>> question_answerer({
... 'question': 'What is the name of the repository ?',
... 'context': 'Pipeline has been included in the huggingface/transformers repository'
... })
{'score': 0.30970096588134766, 'start': 34, 'end': 58, 'answer': 'huggingface/transformers'}除了给出答案,预训练模型还给出了对应的置信度分数、答案在词符化 (tokenized) 后的文本中开始和结束的位置。
使用非默认的其他预训练模型
Hugging Face Models 提供了很多其他模型供我们使用,我们来导入一个非默认的模型nlptown/bert-base-multilingual-uncased-sentiment,这是一个基于BERT的模型,可以做判断正负面情绪的工作:
>>> from transformers import pipeline
>>> classifier = pipeline('sentiment-analysis', model="nlptown/bert-base-multilingual-uncased-sentiment")
>>> print(classifier('I love you more and more each day as time goes by'))
[{'label': '5 stars', 'score': 0.8776088356971741}]
>>> print(classifier('心有领导,永远忠诚'))
[{'label': '5 stars', 'score': 0.6939144730567932}]
>>> print(classifier('我讨厌渣男'))
[{'label': '1 star', 'score': 0.41145384311676025}]可见这个模型会把文本分为1 star到5 star的不同等级。星级越高,该文本表达的情绪越积极。
再来看一个fill-mask填词任务,我们导入的是预训练模型hfl/chinese-roberta-wwm-ext,这也是一基于BERT的模型:
>>> from transformers import pipeline
>>> maskfiller = pipeline('fill-mask', model = "hfl/chinese-roberta-wwm-ext")
>>> print(maskfiller('我爱[MASK]'))
[{'sequence': '我 爱 你', 'score': 0.9170712828636169, 'token': 872, 'token_str': '你'}, {'sequence': '我 爱 他', 'score': 0.02408534474670887, 'token': 800, 'token_str': ' 他'}, {'sequence': '我 爱 她', 'score': 0.014233492314815521, 'token': 1961, 'token_str': '她'}, {'sequence': '我 爱 我', 'score': 0.005949386395514011, 'token': 2769, 'token_str': '我'}, {'sequence': '我 爱 您', 'score': 0.0037280190736055374, 'token': 2644, 'token_str': '您'}]怎么样,是不是很好玩😆😆😆

