从巨潮资讯网爬取2020年上市公司财报
前面说有三个比较官方的财报获取渠道:上交所、深交所、巨潮资讯网。这个巨潮资讯网来头不小,是证监会指定的上市公司信息披露网站,爬它一个免得去爬上交所+深交所,而且看起来比较好爬。
我是从上次看过的30行代码爬取A股上市公司年报这篇文章里面,看到这篇介绍爬取巨潮资讯的文章的。
原码
这篇文章比较复杂,爬巨潮比我们前面爬的内容都要复杂,因为它对财报的下载url做了特殊处理,有一定反爬功能。这篇文章提供的原码如下:
import json
import os
from time import sleep
from urllib import parse
import requests
def get_adress(bank_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': bank_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
'Content-Length': '70',
'User-Agent': 'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 75.0.3770.100Safari / 537.36',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
}
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = r.content
m = str(r, encoding="utf-8")
pk = json.loads(m)
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
print(orgId,plate,code)
return orgId, plate, code
def download_PDF(url, file_name): #下载pdf
url = url
r = requests.get(url)
f = open(bank +"/"+ file_name + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': '',
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'Accept-Encoding': 'gzip,deflate',
'Connection': 'keep-alive',
# 'Content-Length': '216',
'User-Agent': 'User-Agent:Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/533.20.25 (KHTML, like Gecko) Version/5.0.4 Safari/533.20.27',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Accept': 'application/json,text/plain,*/*',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
data = parse.urlencode(data)
print(data)
r = requests.post(url, headers=hd, data=data)
print(r.text)
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list:
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']:
continue
if 'H' in report['announcementTitle']:
continue
else: # http://static.cninfo.com.cn/finalpage/2019-03-29/1205958883.PDF
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:"+pdf_url,"存放在当前目录:/"+bank+"/"+file_name)
download_PDF(pdf_url, file_name)
sleep(2)
if __name__ == '__main__':
# bank_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行', ]
bank_list = ["平安银行"]
for bank in bank_list:
os.mkdir(bank)
orgId, plate, code = get_adress(bank)
get_PDF(orgId, plate, code)
print("下一家~")
print("All done!")跑一下试试,哇真的太棒了,果然能下载到财报。理论上我们只需要采用奥卡姆剃刀原则,改一下它的代码,把bank_list换为我们《2021年上市公司基本信息表》里面的股票简称,然后依次下载pdf到我们的指定目录就可以了。
然而为了学习起见,我们还是研究以下它的代码。
分析
巨潮资讯网下载财报的方式大致是需要先搜索,然后筛选年报,然后进入下载页面。
下载页面有全屏功能,也有下载功能。我们点击右键“检查网页源代码”,搜索一下“公告下载”,在HTML源码中发现这样一行代码:
<el-button size="mini" type="primary" @click="noticeDownload"><i class="iconfont icongonggaoxiazai"></i> 公告下载</el-button>这段代码告诉我们,用户在点击“公告下载”时,网站会调用“noticeDownload”函数。这个函数在哪里呢?直觉告诉我们在这个网页所引用的JavaScript源码里,我们翻到页面最下方,有这两行:
<script src="http://static.cninfo.com.cn/new/js/lib/pdfobject.min.js?v=20210820023809"></script>
<script type="text/javascript" src="http://static.cninfo.com.cn/new/assets/js/disclosure/notice-detail.js?v=20210820023809"></script>分别给出了两份JavaScript代码的地址,我们选择右键“在新标签页中打开链接”,然后果然在第二个链接对应的代码中找到了“noticeDownload”函数,它里面是这样定义的:
noticeDownload: function () {
window.open(path + '/announcement/download?bulletinId=' + announcementId + '&announceTime=' + announcementTime);
},意思就是在windows端打开一个窗口,就是我们的下载窗口,而要下载的pdf财报的地址就是这几个关键字拼接而来的。这几个关键字的内容在我们刚才打开的那个HTML中都可以找到。
于是我们获得了下载PDF的链接,只要访问这个链接,就可以下载PDF,类似于之前从WinGo下载上市公司2001-20019年财务报告的做法。
我们点击下载年报的时候,看到的链接也是这种模式的。并且我们可以看到,对于同一企业的不同年份,announcementId和announcementTime都是不同的,而得到这两个变量,就能得到下载链接。
获取announcementId和announcementTime
想想我们是从哪里来的,可能就可以知道怎么获取这两个值,上一页有所有年份的财报。
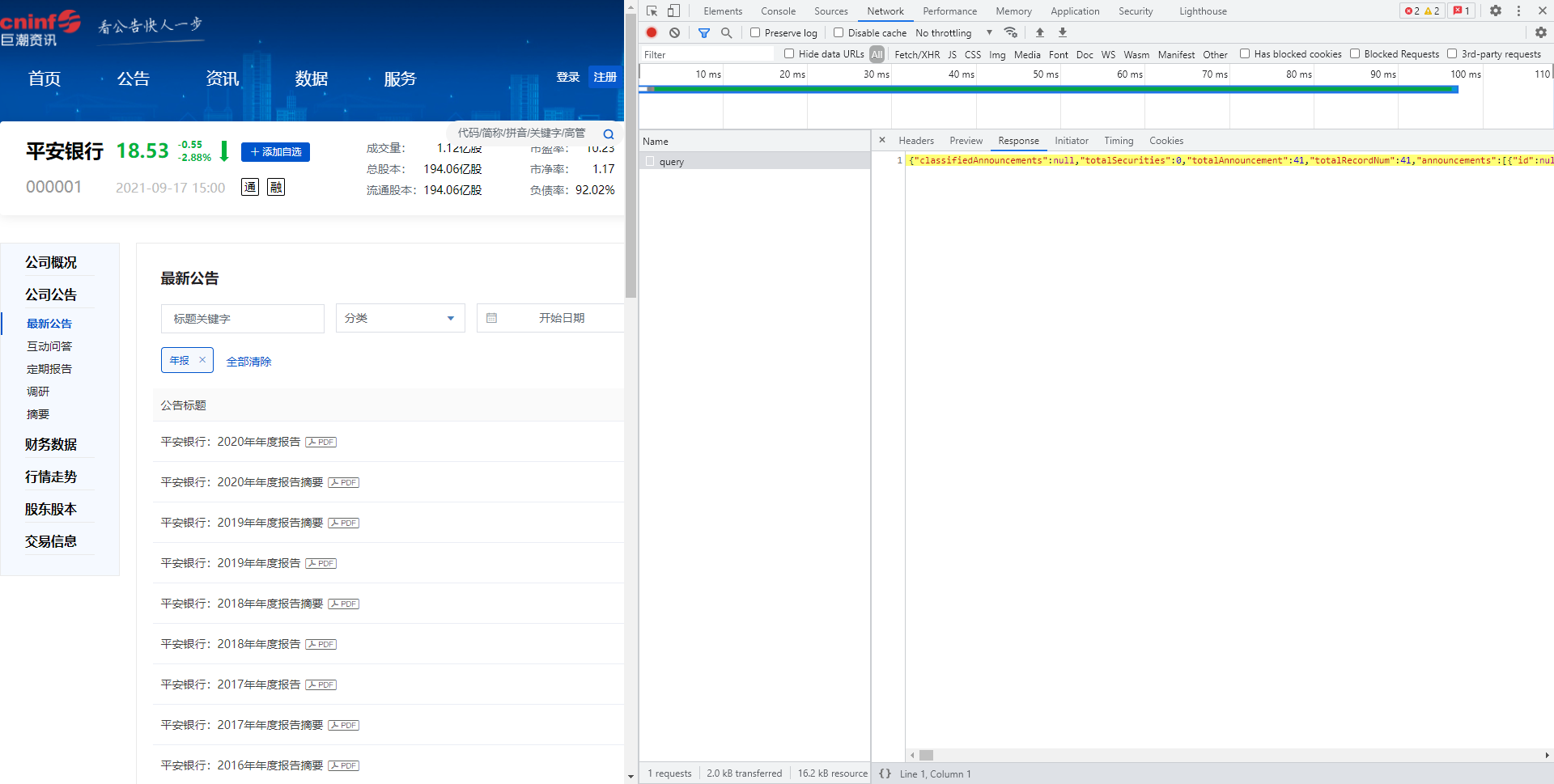
我们回到这个页面,右键“检查”,选择Network,在“分类”中选择年报,此时会记录下一条query,这是浏览器向服务器发送请求的信息,包括请求头、请求内容、回应内容等等,在回应内容Response中我们显然可以看到各种不同年份的announcementId和announcementTime:
然后我们点击Headers看看请求内容与请求头,可以看到:
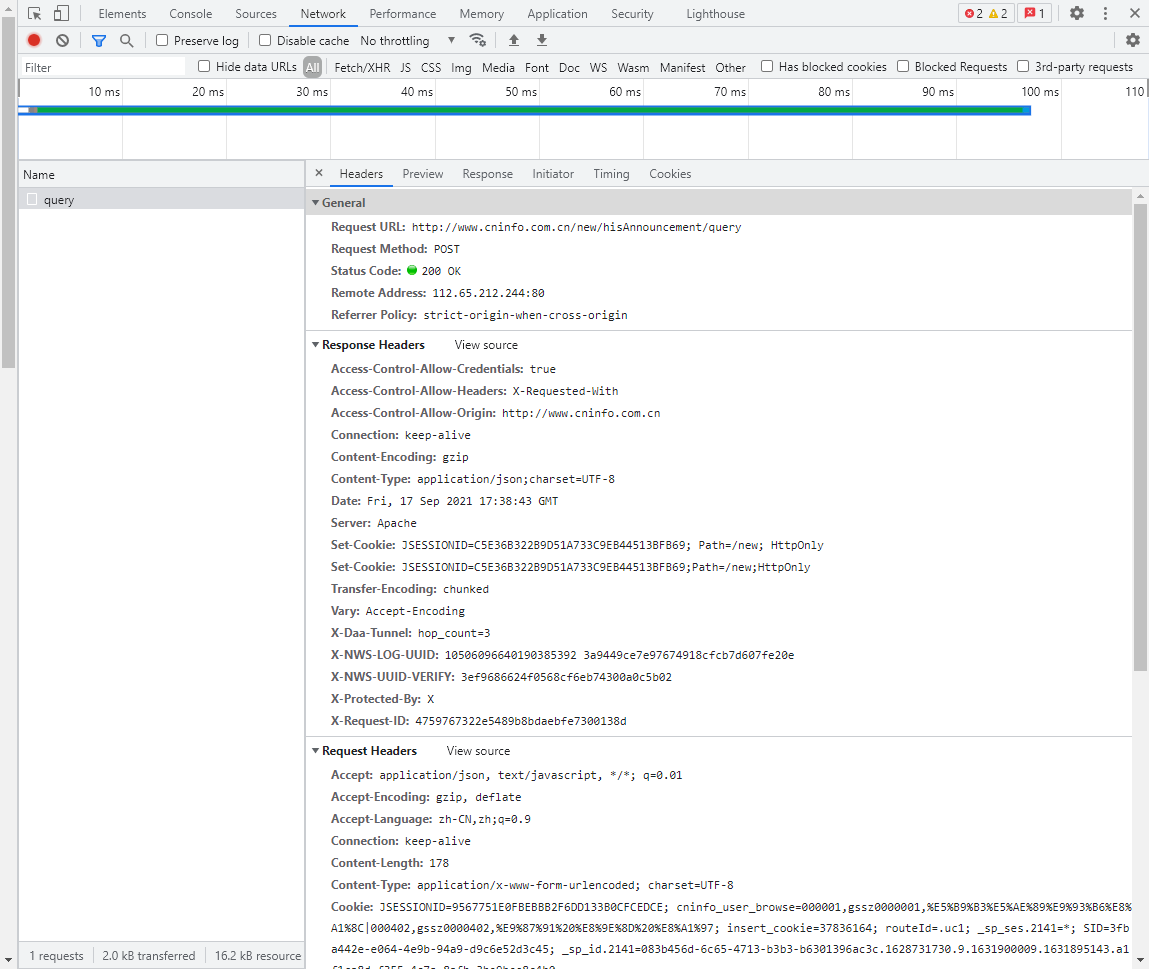
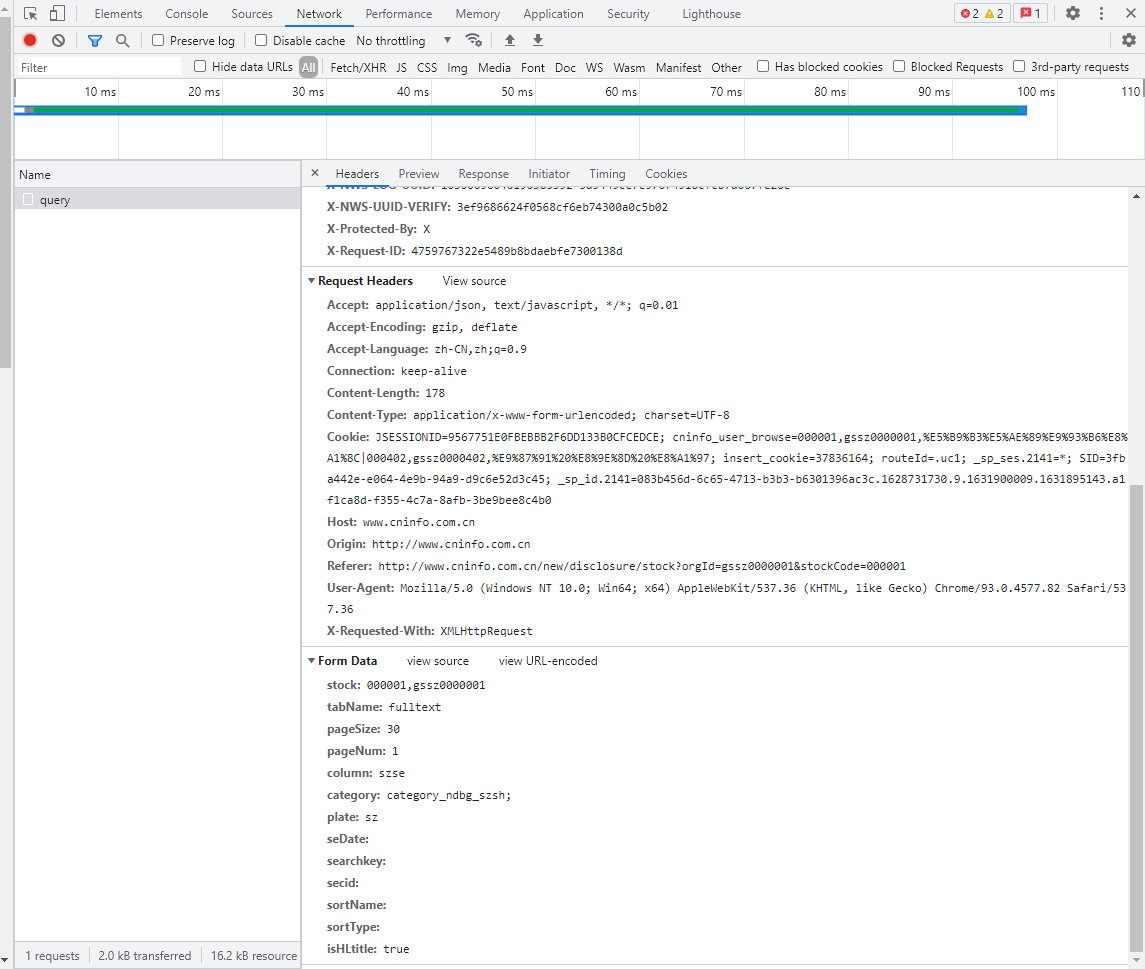
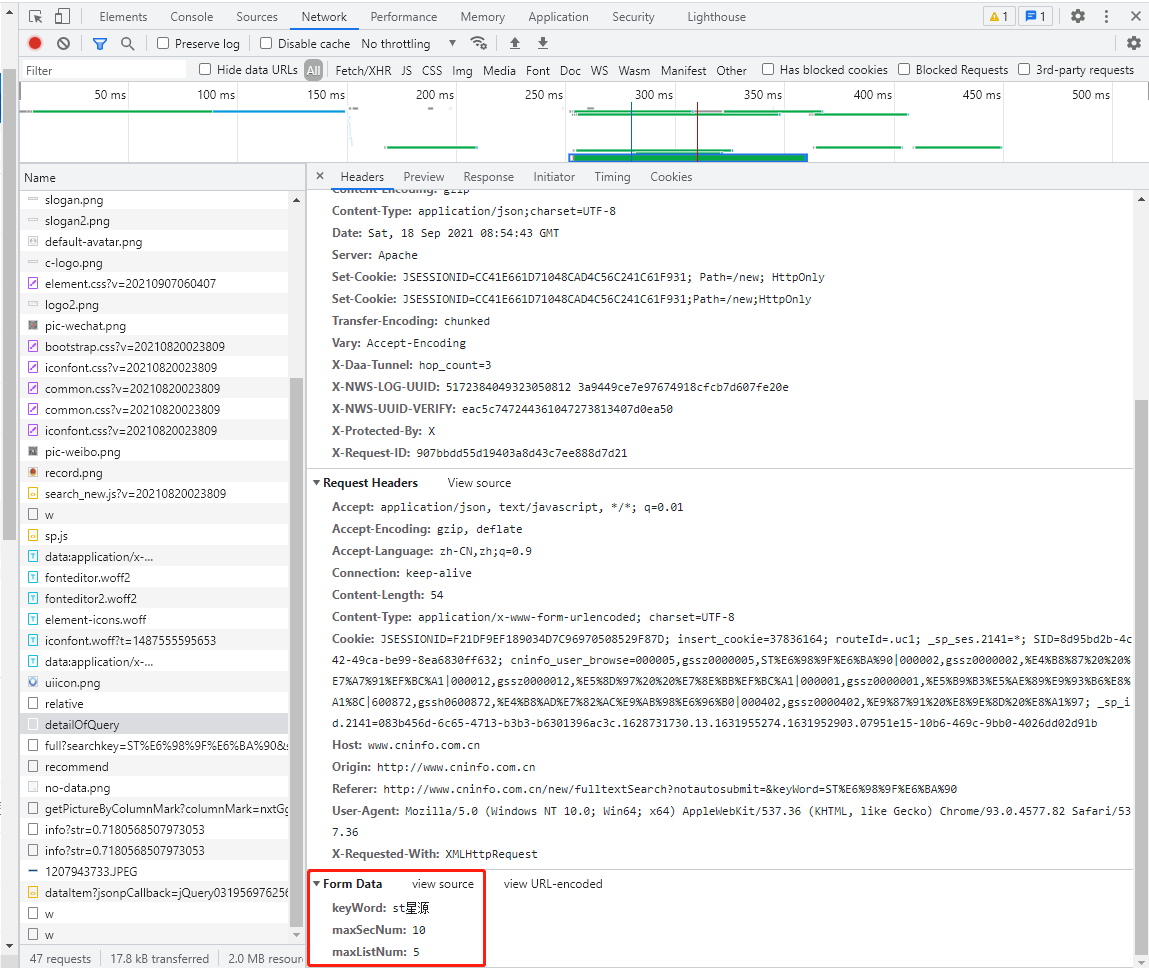
其中Form Data是浏览器向Request URL发送的请求内容,Request Headers是请求头。我们前面的爬虫都是基于get方法的,这里要基于post方法来做,因为要涉及到构造请求头。这就是原代码中get_PDF()函数所做的事情。
请求头都容易做,请求内容是个性的,多看几个就会发现,stock和column是可变的,其他不可变。虽然变化有规律,但是原代码采用了更炫技的方法来实现:构建另一个post来获取。
获取stock与plate
二二三四再来一次,我们在搜索页面打开检查功能的Network项,进行一次搜索,浏览器为我们记录下了很多与服务器的互动过程:
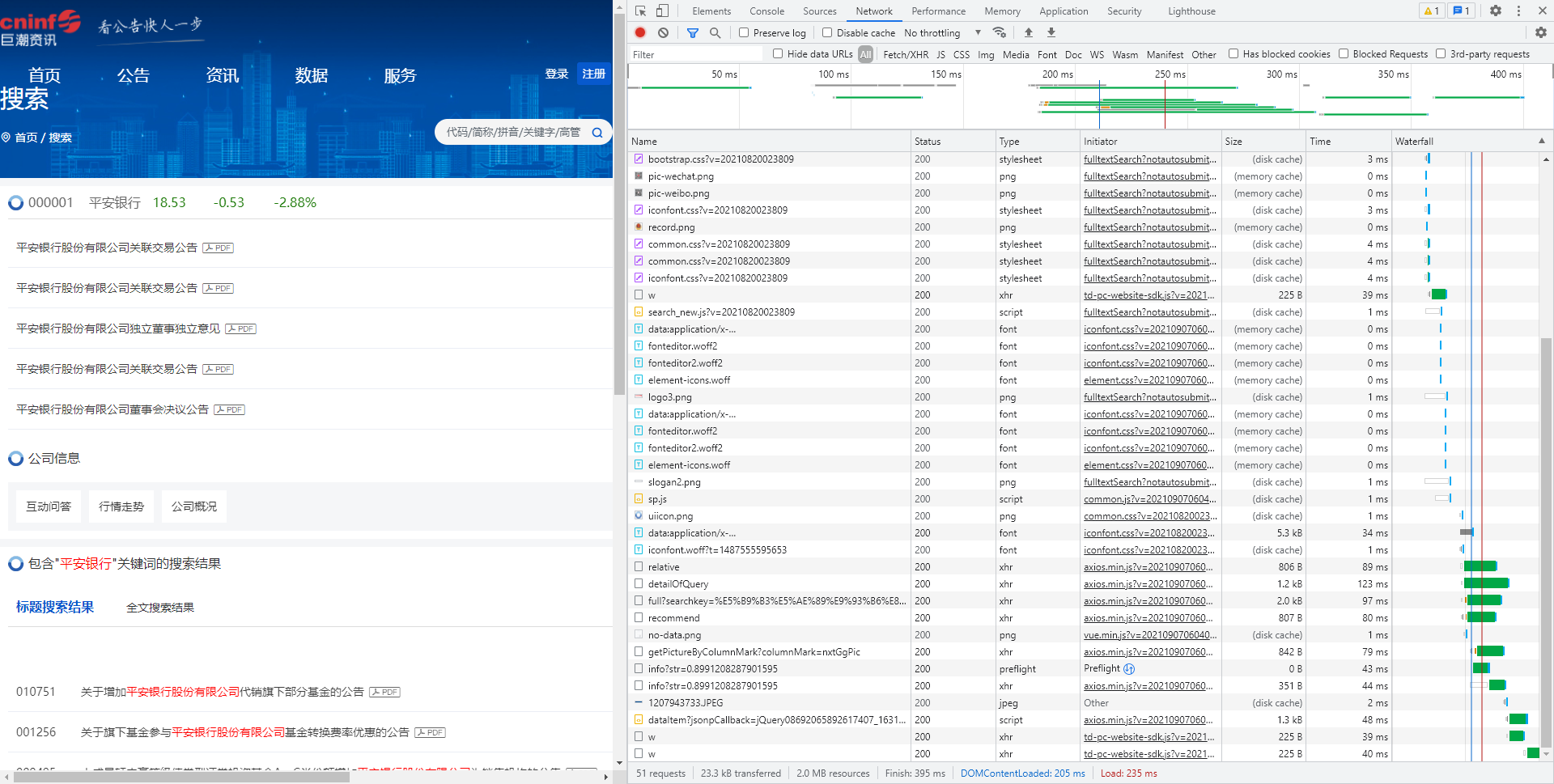
原码作者已经贴心地为我们找到了,detailOfQuery这一项得到的Response包含了我们构建stock和column所需要的内容。那么我们只需要先做一次post,得到这个Response就可以了,我们看一下这个post的General与请求头、请求内容:
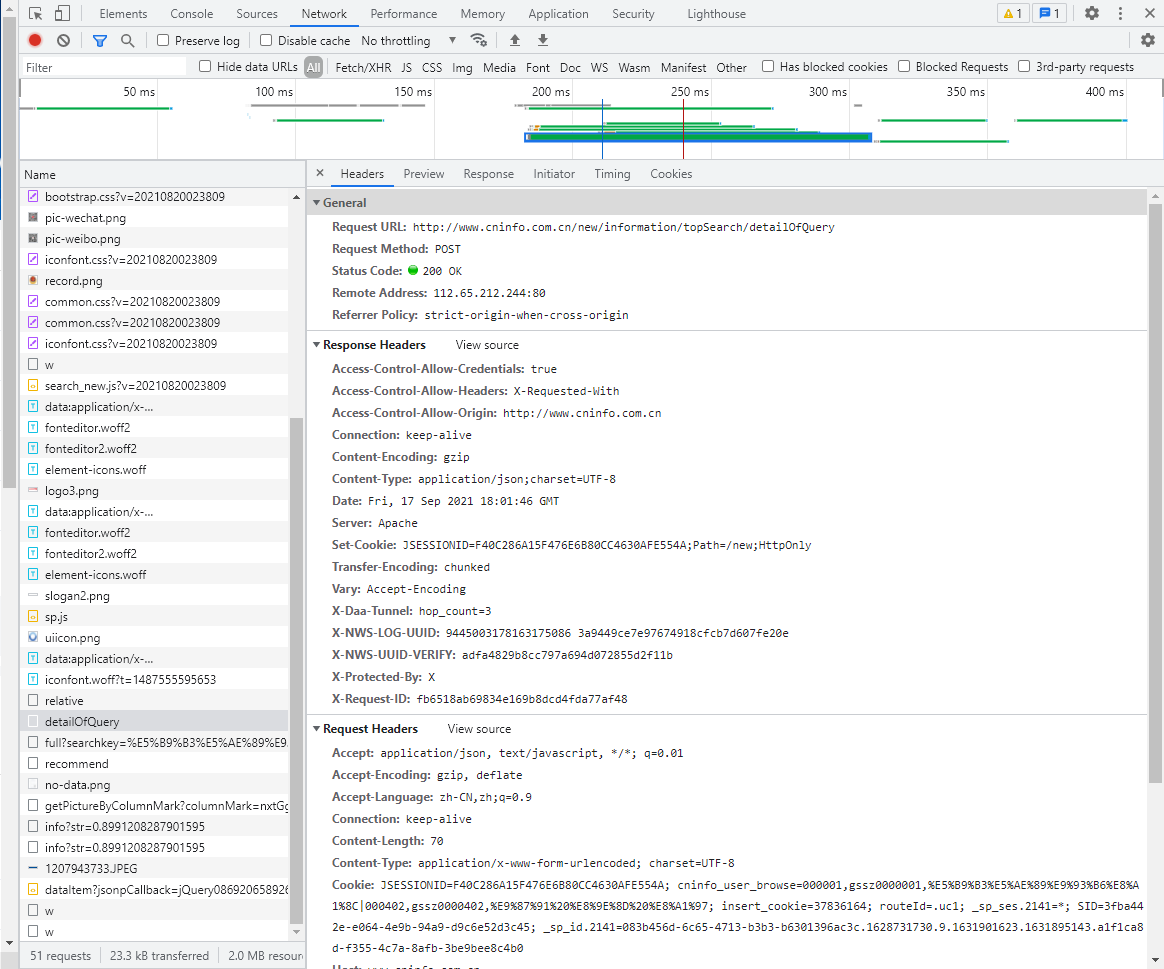
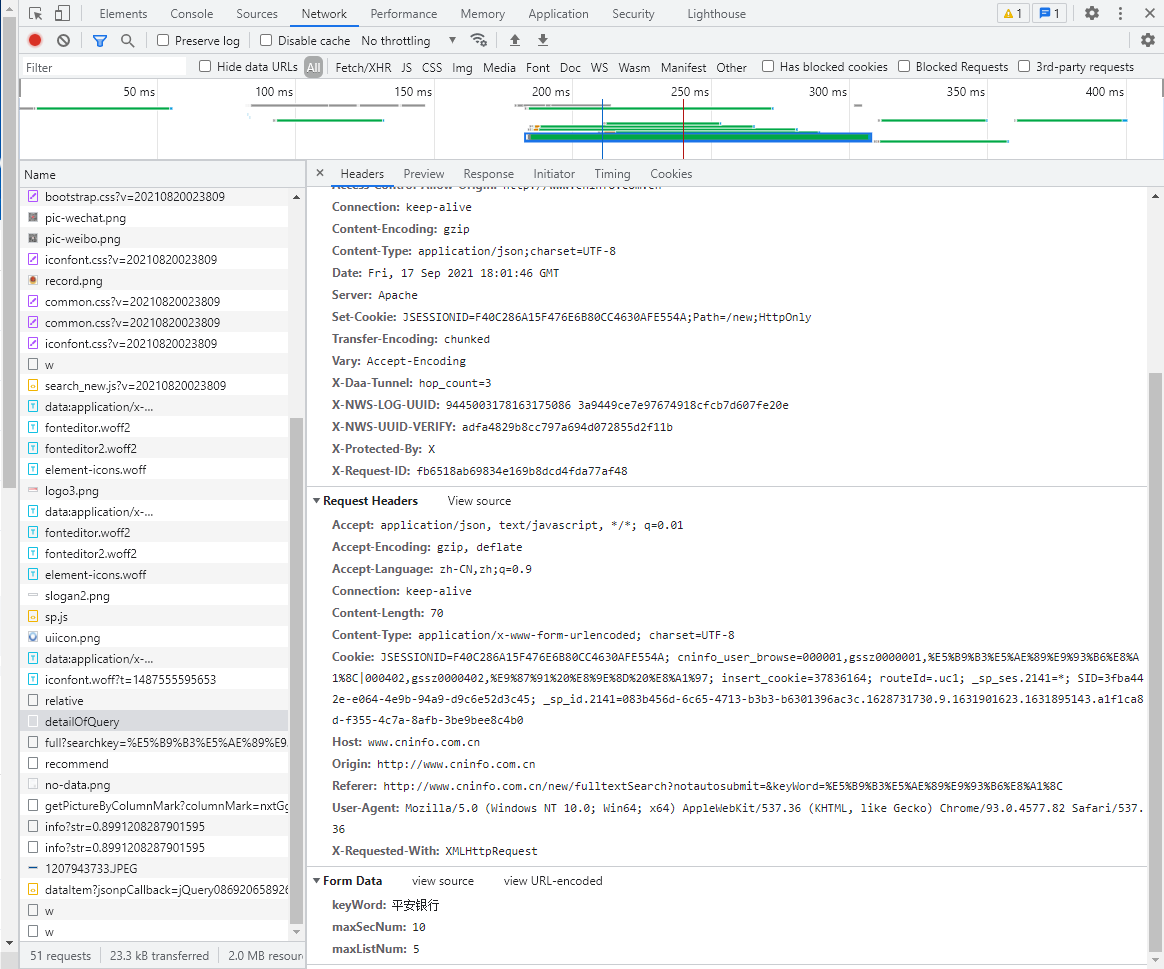
简单易懂,直接构建即可。这就是原码get_adress()函数做的事情。
至此我们就弄明白了原码的思路和做法。
还有另一种更为简单粗暴的方法,就是直接查看下载链接:
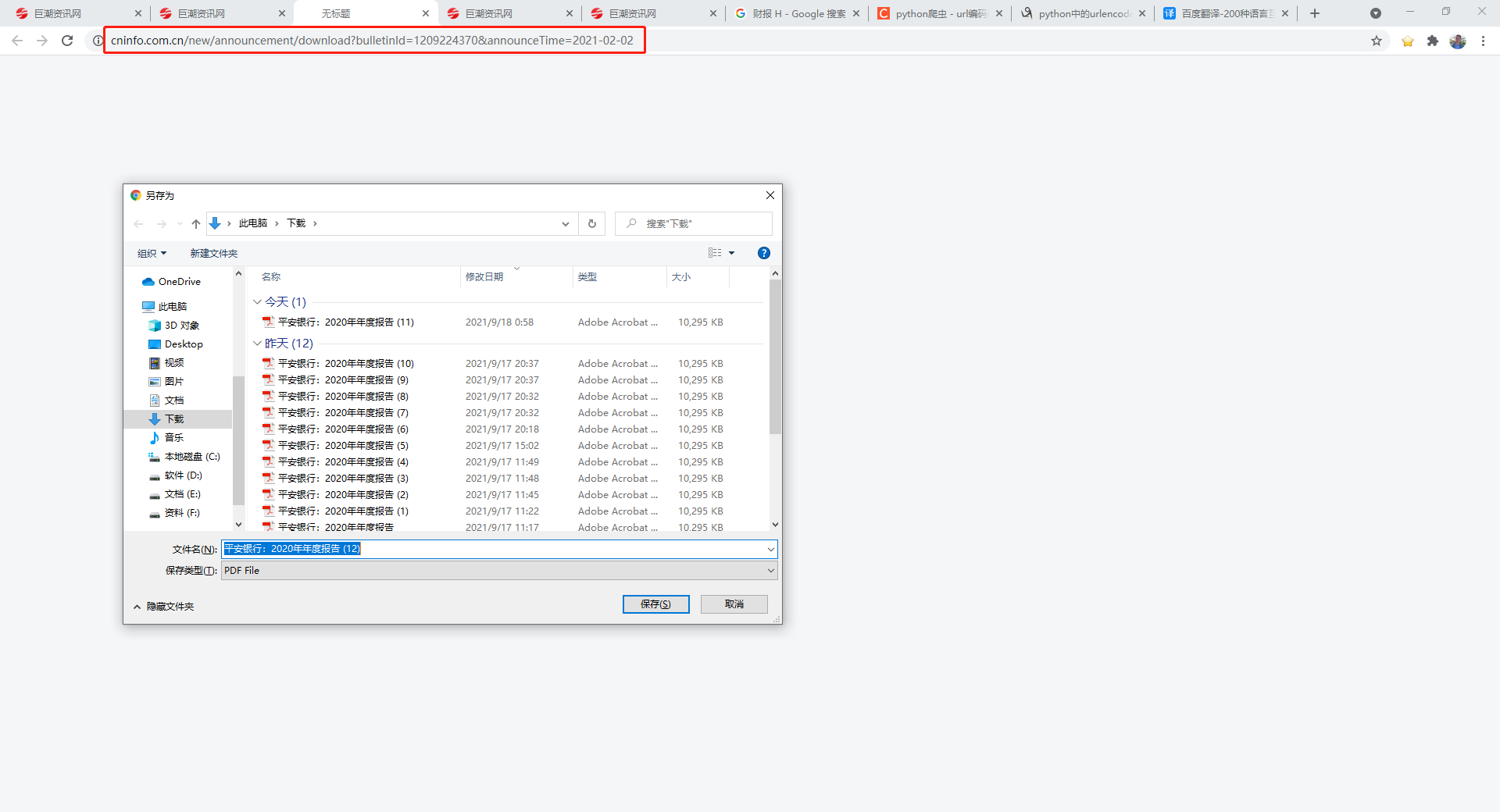
同样可以发现,下载链接就是在http://www.cninfo.com.cn/new后面拼接了这一小节获得的Response的adjunctUrl字段,代码里就用的这种方式。
由于原码时间久远,已经有些陈旧,我根据浏览器上记录下的信息更改了原码并做了注释,并把代码改为只获取2020年财报,下载到指定目录,并且优化了一下财报命名格式:
import json
import os
from time import sleep
from urllib import parse
import requests
def get_adress(company_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': company_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '70',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
# 'Referer': referer, # 用于告诉服务器我们是从哪个页面跳转到这个页面来的,这里可能并不需要
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Pragma': 'no-cache', # 强制要求缓存服务器在返回缓存的版本之前将请求提交到源头服务器进行验证。
# 'X-Requested-With': 'XMLHttpRequest', # 用于区分同步请求(等待回应之后再发送下一个数据包) 异步请求(不等待回应) 没有这一项表示同步请求
# 'Cookie': cookie, # cookie是与用户个人信息有关的内容,这里不需要
}
r = requests.post(url, headers=hd, data=parse.urlencode(data))
m = str(r.content, encoding="utf-8") # 获取响应内容转换编码格式,正常显示中文
pk = json.loads(m) # 将得到的JSON格式的响应转变为Python中可以使用的对象
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name, company, orgId): #下载pdf
url = url
r = requests.get(url)
f = open('D:\\爬取巨潮资讯网\\'+ company + file_name + "_" + orgId + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code, company):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
if plate == 'sse':
sh_or_sz = 'sh'
else:
sh_or_sz = 'sz'
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': sh_or_sz,
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
# 'Content-Length': '216', # 这一项不同企业不一定相同,作者注释掉了
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
r = requests.post(url, headers=hd, data=parse.urlencode(data)) # parse.urlencode()这一步作用是把data进行解析,并不是必要的,但是加上可以方便了服务器了解我们的询问
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list: # 遍历所有财报
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']: # 筛掉摘要和2000年前的财报
continue
if 'H' in report['announcementTitle']: # 这个其实我没太明白,但是作用是筛掉名称中含有H的财报
continue
if "2020" in report['announcementTitle']: # 2020年财报
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
print("正在下载:" + company + file_name)
download_PDF(pdf_url, file_name, company, orgId)
sleep(2)
company_list = [ '中信银行', '兴业银行', '平安银行','民生银行', '华夏银行','交通银行', '中国银行', '招商银行', '浦发银行','建设银行', ]
for company in company_list:
orgId, plate, code = get_adress(company)
get_PDF(orgId, plate, code, company)加入上市企业列表
现在我们要做的就是更新一下company_list啦,我们只需要再次读取《2021年上市公司基本信息表》,重新修改代码。
另外我还发现,http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery的query data中的企业简称中如果包含英文字母,默认都是转换为小写了,星号也需要去掉,原代码里也没有注意到这一点,所以需要改过来。也加入适当的休眠,反爬虫。
最终代码如下:
import json
import os
from time import sleep
from urllib import parse
import requests
import xlrd
import time
dir = 'D:\\爬取巨潮资讯网\\' # 这个目录需要自行创建并指定
def get_adress(company_name):
url = "http://www.cninfo.com.cn/new/information/topSearch/detailOfQuery"
data = {
'keyWord': company_name,
'maxSecNum': 10,
'maxListNum': 5,
}
hd = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Content-Length': '70',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
# 'Referer': referer, # 用于告诉服务器我们是从哪个页面跳转到这个页面来的,这里可能并不需要
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'Pragma': 'no-cache', # 强制要求缓存服务器在返回缓存的版本之前将请求提交到源头服务器进行验证。
# 'X-Requested-With': 'XMLHttpRequest', # 用于区分同步请求(等待回应之后再发送下一个数据包) 异步请求(不等待回应) 没有这一项表示同步请求
# 'Cookie': cookie, # cookie是与用户个人信息有关的内容,这里不需要
}
r = requests.post(url, headers=hd, data=parse.urlencode(data))
m = str(r.content, encoding="utf-8") # 获取响应内容转换编码格式,正常显示中文
pk = json.loads(m) # 将得到的JSON格式的响应转变为Python中可以使用的对象
orgId = pk["keyBoardList"][0]["orgId"] #获取参数
plate = pk["keyBoardList"][0]["plate"]
code = pk["keyBoardList"][0]["code"]
return orgId, plate, code
def download_PDF(url, file_name, company, orgId): #下载pdf
url = url
r = requests.get(url)
f = open(dir + file_name.upper() + "_" + orgId + ".pdf", "wb")
f.write(r.content)
def get_PDF(orgId, plate, code, company):
url = "http://www.cninfo.com.cn/new/hisAnnouncement/query"
if plate == 'sse':
sh_or_sz = 'sh'
else:
sh_or_sz = 'sz'
data = {
'stock': '{},{}'.format(code, orgId),
'tabName': 'fulltext',
'pageSize': 30,
'pageNum': 1,
'column': plate,
'category': 'category_ndbg_szsh;',
'plate': sh_or_sz,
'seDate': '',
'searchkey': '',
'secid': '',
'sortName': '',
'sortType': '',
'isHLtitle': 'true',
}
hd = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
# 'Content-Length': '216', # 这一项不同企业不一定相同,作者注释掉了
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.cninfo.com.cn',
'Origin': 'http://www.cninfo.com.cn',
'Pragma': 'no-cache',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
# 'Cookie': cookies
}
r = requests.post(url, headers=hd, data=parse.urlencode(data)) # parse.urlencode()这一步作用是把data进行解析,并不是必要的,但是加上可以方便了服务器了解我们的询问
r = str(r.content, encoding="utf-8")
r = json.loads(r)
reports_list = r['announcements']
for report in reports_list: # 遍历所有财报
if '摘要' in report['announcementTitle'] or "20" not in report['announcementTitle']: # 筛掉摘要和2000年前的财报
continue
if 'H' in report['announcementTitle']: # 这个其实我没太明白,但是作用是筛掉名称中含有H的财报
continue
if "2020" in report['announcementTitle']: # 2020年财报
pdf_url = "http://static.cninfo.com.cn/" + report['adjunctUrl']
file_name = report['announcementTitle']
if company not in file_name:
file_name = company + file_name
print("正在下载:" + file_name.upper())
download_PDF(pdf_url, file_name, company, orgId)
break # 下载且只下载一个
sleep(2)
file = '2021年上市公司基本信息表.xlsx'
wb = xlrd.open_workbook(filename=file)# 打开表格文件
errors = open('C:\\Users\\15617\\Desktop\\'+'异常信息_巨潮资讯网.txt', 'a', encoding='utf-8')
sheet1 = wb.sheet_by_index(0)# 通过索引获取表格
for i in range(1, sheet1.nrows):
print(i, end='\t')
company = sheet1.row(i)[1].value.strip('*').lower()
try:
orgId, plate, code = get_adress(company)
get_PDF(orgId, plate, code, company)
except:
print("出现异常!"+company)
errors.write(company+'\n')
time.sleep(2)注意我把下载目录放到了代码最前面。代码可以正常运行。总共爬取了4206个公司2020年的年报,发现261个异常,经查验,都是没有在巨潮发布年报的公司。
我承认这次有点复杂,不过正好极大地丰富了我们的知识面,不是吗💪💪💪

