从Tushare获取上市公司简介
经过一些简单的百度和谷歌就可以知道,Python常用的金融数据包包括Tushare、BaoStock等等,我们用谷歌搜一下“tushare 上市公司信息”:
打开第一个网页,这是Tushare社区的一个文档页面,很欣慰,Tushare提供了一个公司简介参数:
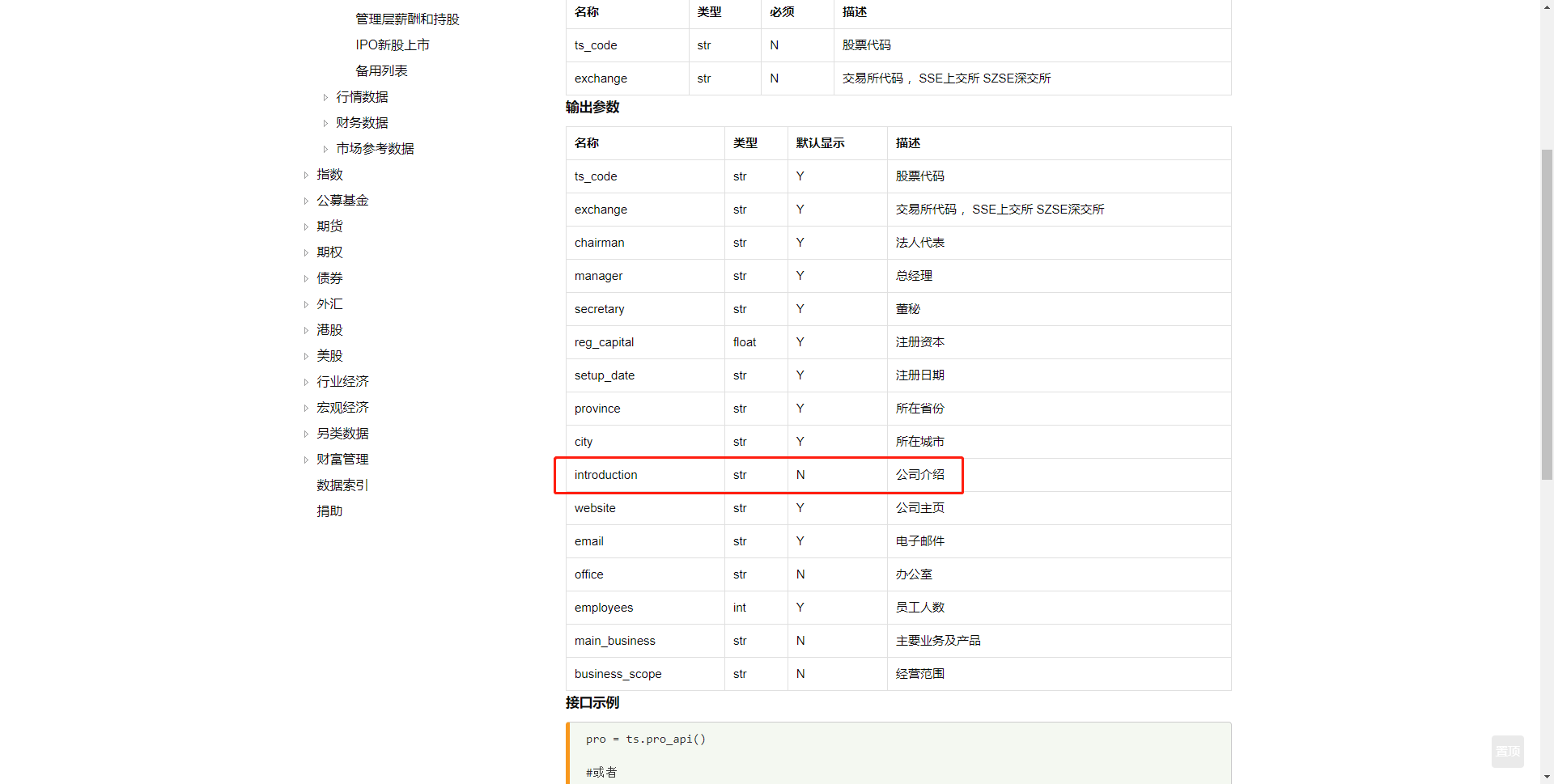
很好,我们来试一下看看这里的公司简介是什么样的。
原代码
文档提供了一段样例代码:
pro = ts.pro_api()
#或者
#pro = ts.pro_api('your token')
df = pro.stock_company(exchange='SZSE', fields='ts_code,chairman,manager,secretary,reg_capital,setup_date,province')运行这段代码之前需要安装tushare:
pip install tushare安装完毕后,直接运行这段代码会提示:
请设置tushare pro的token凭证码,如果没有请访问https://waditu.com注册申请我们需要注册一个社区账号,然后进行个人信息设置,得到token和积分,才能调用这个接口。比如我操作之后执行这段代码就成功了:
import tushare as ts
pro = ts.pro_api('c9c184bef0644923bc05e6e096d71fbf929c731163be9db98d858a69')
df = pro.stock_company(exchange='SZSE', fields='ts_code,chairman,manager,secretary,reg_capital,setup_date,province')简单易懂,稍微看看文档就明白,SSE上交所,SZSE深交所,fields参数是筛选我们想要的参数。
修改代码
我们稍微改一下代码:
import tushare as ts
pro = ts.pro_api('c9c184bef0644923bc05e6e096d71fbf929c731163be9db98d858a69')
ssedf = pro.stock_company(exchange='SSE', fields='ts_code,introduction')
szsedf = pro.stock_company(exchange='SZSE', fields='ts_code,introduction')
print(ssedf)
print(szsedf)这样就得到了我们最在意的introduction参数的内容。
接下来该怎么办呢?股票代号是唯一的,可以用于跟我们以前的爬取结果整合;为了提取introduction的内容,我们首先需要知道ssedf和szsedf分别是什么类的对象,才好对症下药。谷歌一下“Python 获取数据类型”就可以知道,可以借助type()函数:
print(type(ssedf))
print(type(szsedf))然后我们就知道二者都是padas包里面的Dataframe类型。
对于这个类型小油油是比较熟悉的,因为比较经典。参见我的这篇早期的博文:pandas.Dataframe增删改查详细操作。这里简单介绍几个使用方式:
print(ssedf.shape[0]) # 行数
print(ssedf.loc[0, 'ts_code']) # 第0行的ts_code列的内容
print(ssedf.loc[0, 'introduction']) # 第0行的introduction列的内容有这两种用法就可以满足我们的基本需求了。
保存为文本
接下来就是我们熟悉的操作了,把introduction保存出来,便于后续操作。比较遗憾的是Tushare没有提供公司名,我们就去掉ts_code点号后面的内容,作为文件名吧:
import pandas as pd
import tushare as ts
pro = ts.pro_api('c9c184bef0644923bc05e6e096d71fbf929c731163be9db98d858a69')
ssedf = pro.stock_company(exchange='SSE', fields='ts_code,introduction')
szsedf = pro.stock_company(exchange='SZSE', fields='ts_code,introduction')
df = pd.concat([ssedf, szsedf], ignore_index=True) # 这是一个Dataframe按列合并的操作,ignore_index=True表示重新排序
dir = 'D:\\Tushare导出\\' # 这个目录需要自行创建并指定
for i in range(df.shape[0]):
print(i)
name = df.loc[i, 'ts_code'][:6]
text = df.loc[i, 'introduction']
fh = open(dir+name+'.txt', 'w', encoding='utf-8')
fh.write(text)
fh.close()这里我们把ssedf和szsedf合并,然后对每一行获取ts_code和introduction,ts_code取前6位的股票编号作为我们的文件名,保存到dir目录下。
然而执行这段代码到第427行会报错:
427
Traceback (most recent call last):
File "test.py", line 18, in <module>
fh.write(text)
TypeError: write() argument must be str, not None意思是说df中有的行的introduction为None,即啥也没有,那么我们就判断一下了,当introduction值为None或者为’’空字符串时,就不保存,并且输出股票代码到一个指定文件中。我认为股票代码是不会为空的,如果能为空就算它狠,我就该换工具包了,我这里就不判断了。
重新写一下代码:
import pandas as pd
import tushare as ts
pro = ts.pro_api('c9c184bef0644923bc05e6e096d71fbf929c731163be9db98d858a69')
ssedf = pro.stock_company(exchange='SSE', fields='ts_code,introduction')
szsedf = pro.stock_company(exchange='SZSE', fields='ts_code,introduction')
df = pd.concat([ssedf, szsedf], ignore_index=True) # 这是一个Dataframe按列合并的操作,ignore_index=True表示重新排序
dir = 'D:\\Tushare导出\\' # 这个目录需要自行创建并指定
empty = open('C:\\Users\\15617\\Desktop\\'+'空信息_Tushare.txt', 'a', encoding='utf-8')
for i in range(df.shape[0]):
print(i)
name = df.loc[i, 'ts_code'][:6]
text = df.loc[i, 'introduction']
if text is None or text=='':
empty.write(name+'\n')
continue
fh = open(dir+name+'.txt', 'w', encoding='utf-8')
fh.write(text)
fh.close()
empty.close()运行一下即可。跑的速度非常快,比百度百科快很多,我这里跑下来一共获得了4637个有效文件。
后续如果有必要的话可以根据股票编号,结合我们的《2021年上市公司基本信息表》,用Python查询股票编号对应的公司名称,然后把百度百科爬取的结果和Tushare导出的结果整合起来。
确实很简单,easy!小仙女要加油喔😆😆😆

